Interactive Text Summarization using Explorable MMR
Satvik Chekuri, Yuan Li, Daniel Manesh, and Syed Muhammad Farhan
Video Demo
MMR in Interactive Text Summarization
Text summarization is the process of summarizing concrete information in large texts for quicker examination and consumption. The resulting short, informative summaries can help readers determine whether the documents are within their interest before going into details.
A common approach is Extractive Text Summarization. The main goal is to identify the significant sentences of the original document and add them to the summary. However, this task can be challenging and time-consuming even to the most experienced writer/reporter. It typically requires that person to go through the entire document to locate those key sentences.
MMR can help the writer locate those key sentences based on the most relevant words. The idea behind this is that words of higher frequency are more significant than others. Hence, the sentences containing highly frequent are more important. When the user specifies a query including key terms, MMR can rank sentences based on their relevance to the searched query. After the user selects some sentences, with an adjustable λ factor, they can further choose between accuracy (in terms of relevancy to the search query) and diversity (as compared with the selected sentences).
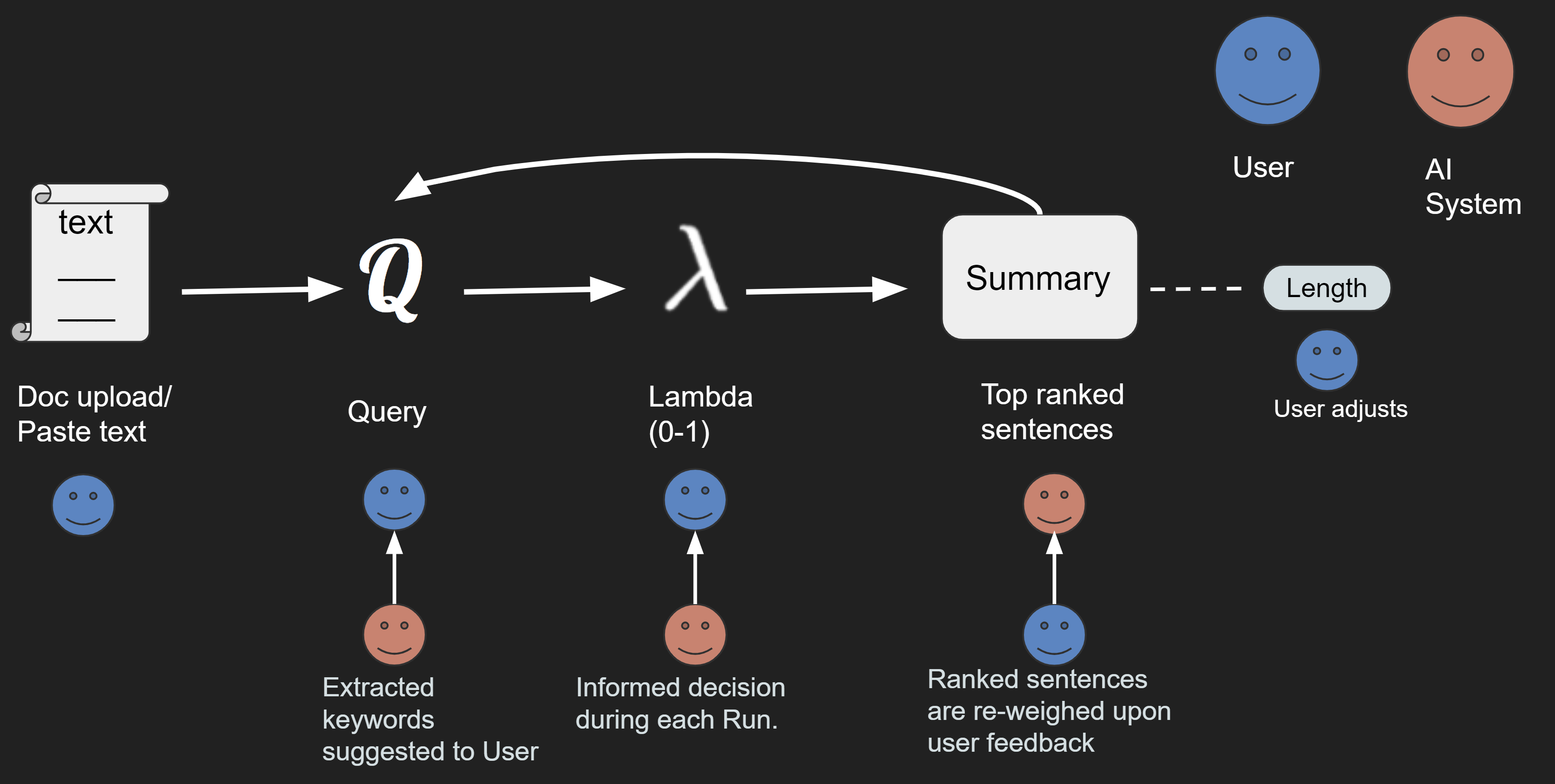
Worflow
The below figure depicts the workflow of our explorable MMR system. We can observe how the two actors (i.e., Human and AI) part of this workflow complement each other in summarizing text.
Maximal Marginal Relevance (MMR) Explained
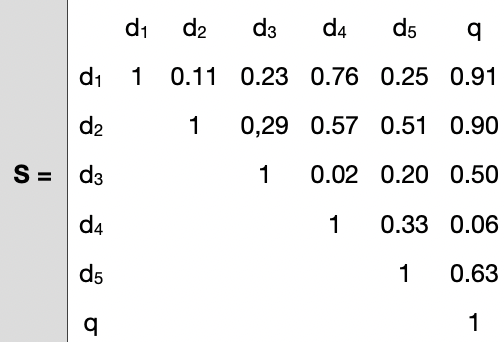
Assume that we are given a database of 5 documents di and a query q, and we calculated, given a symmetrical similarity measure, the similarity values as below. Further assume that λ is given by the user to be 0.5:
Initially our result set S is empty. Therefore the second half of the equation, which is the max pairwise similarity within S, will be zero. For the first iteration, MMR equation reduces to:
MMR = arg max (sim (di, q))
d1 has the maximum similarity with q, therefore we pick it and add it to S. Now, S = {d1}.
Since S = {d1}, finding the maximum distance to an element in S to a given di is simply sim(d1,di).
For d2:
sim(d1, d2) = 0.11
sim (d2, q) = 0.90
Then MMR = 0.90 – (1-λ)0.11 = 0.4225
Similarly MMR values for d3, d4, d5 are 0.135, -0.35 and 0.19 respectively. Since d2 has the maximum MMR, we add it to S. Now S = {d1, d2}.
This time S = {d1, d2}. We should find max of sim (di, d1) and sim (di, d2) for the second part of the equation.
For d3:
max{sim (d1, d3), sim (d2, d3)} = max {0.23, 0.29} = 0.29
sim (d3, q) = 0.50
Then MMR = 0.5*0.5 - 0.5*0.29 = -0.0725
Similarly MMR values for d4 and d5 are -0.35 and 0.06 respectively. Since d2 has the maximum MMR, we add it to S. Now S = {d1, d2}.
d3 has the maximum MMR, therefor S = {d1, d2, d3}.
If we didn't have diversity at all (λ = 1), then our S would have been {d1, d2, d5}.